Shariar Kabir
I lead the AI Research and Engineering team at Celloscope Ltd where we develop production-grade AI-based solutions that are safe, reliable, and trustworthy. I completed my BSc in Computer Science and Engineering, from Bangladesh University of Engineering and Technology (BUET).
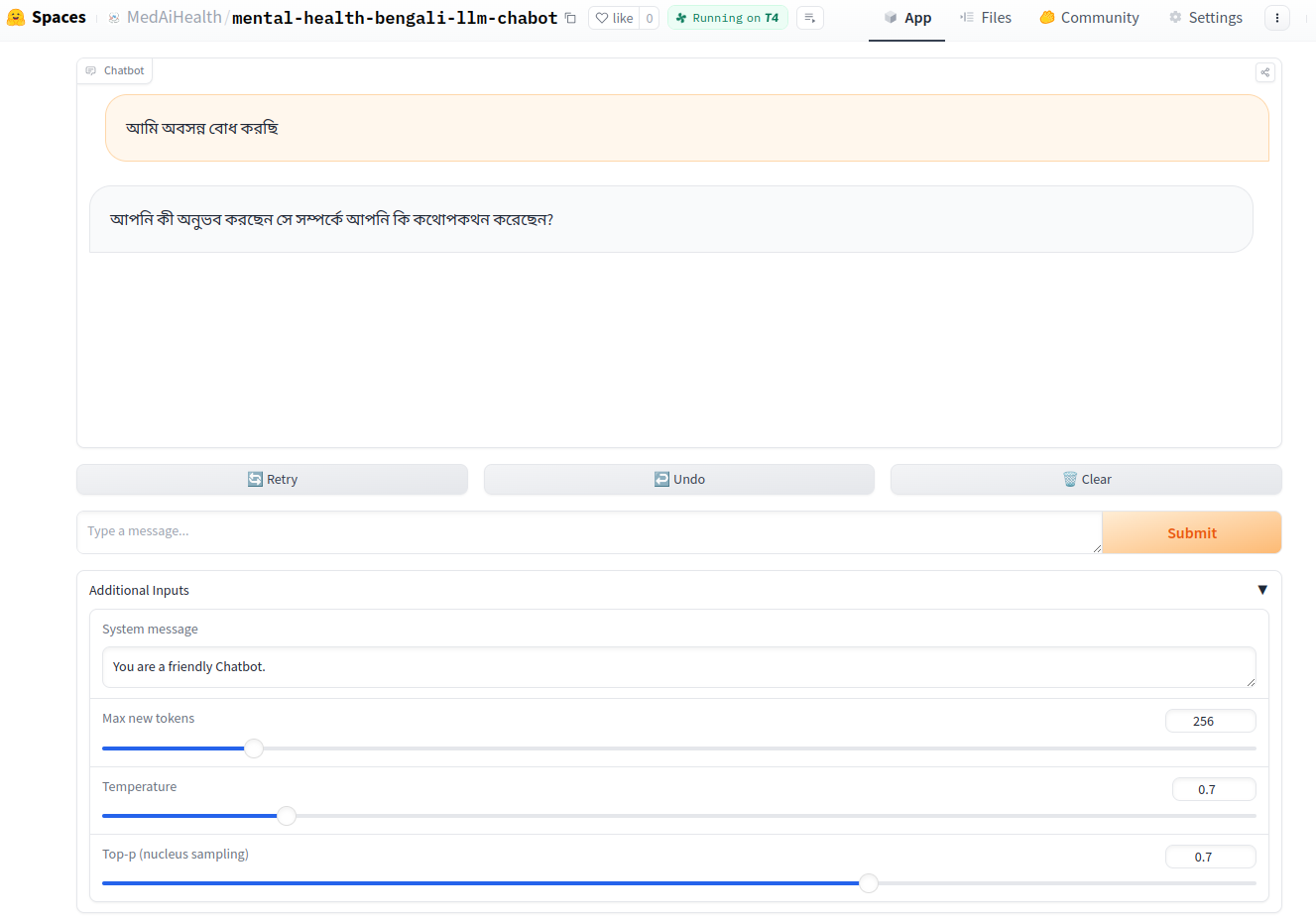
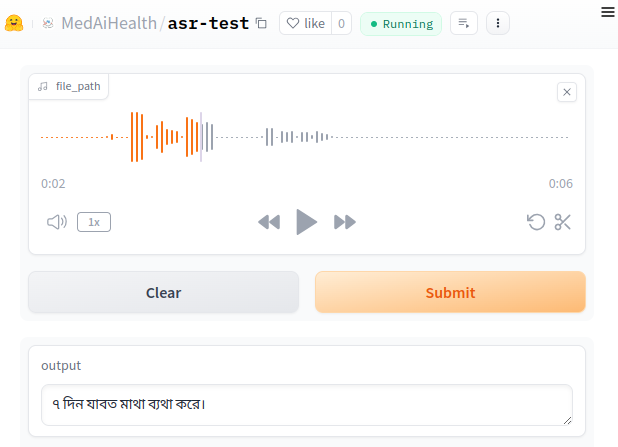
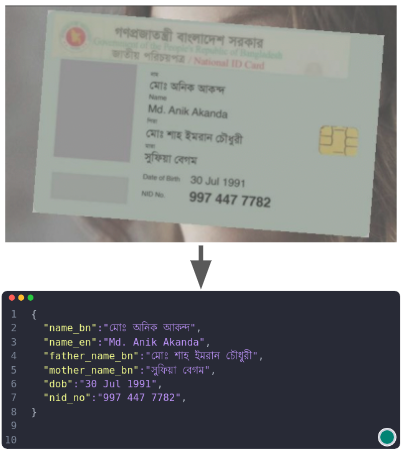
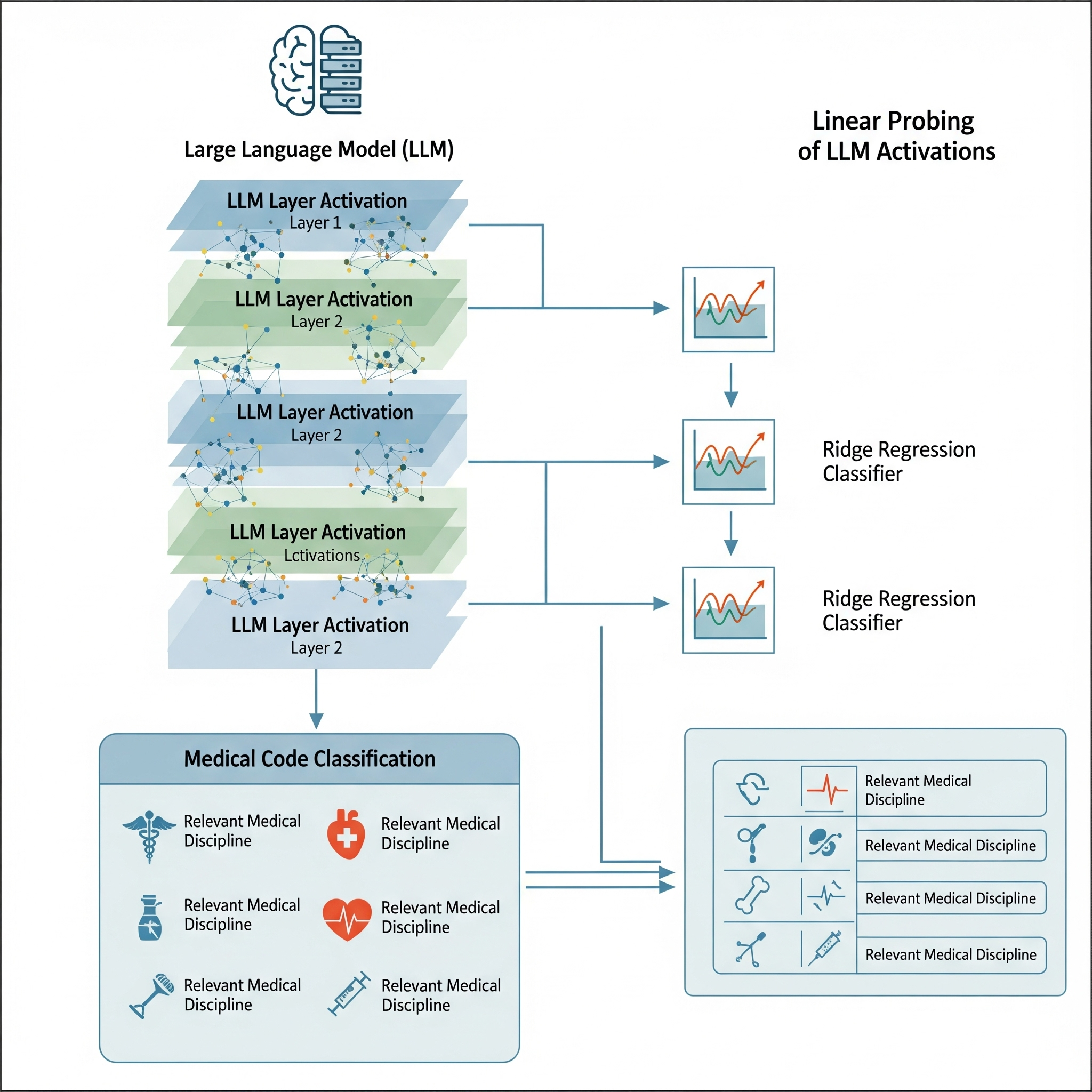
My work focuses on interpretability and behavioral evaluation of large language models, with related questions of safety and robustness. Currently, I am exploring how LLMs behavior evolve over longer context such as in multi-turn interactions, how their internal mechanisms can be made interpretable, and how fairness can be ensured through principled interventions. Previously, I worked on inclusive AI systems for low-resource languages, including Bengali medical ASR and document understanding tools. My long-term goal is to build methods that make AI systems not only capable but also transparent, stable, and socially aligned. My detailed CV can be found Here.

News
- [12/23/2025] Our paper AgnoSVD: Dynamic Resource Allocation for Serverless Workloads using Collaborative Filtering has been published in the journal of ARRAY.
- [4/25/2025] Our paper titled: Do Words Reflect Beliefs? Evaluating Belief Depth in Large Language Models is available on arXiv.
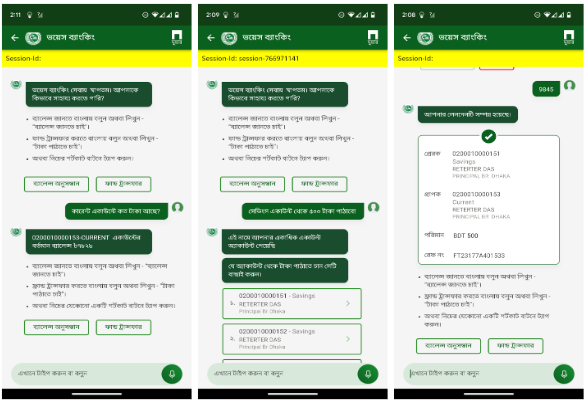
- [9/22/2024] Our solution AmarDoctor was selected at the 2024 Global Health Equity Challenge.
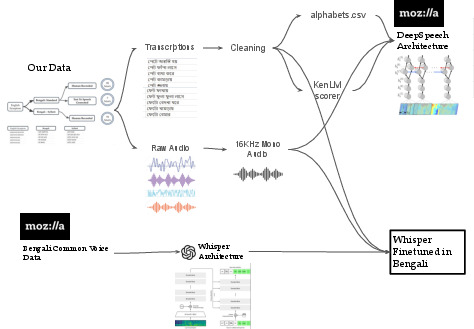
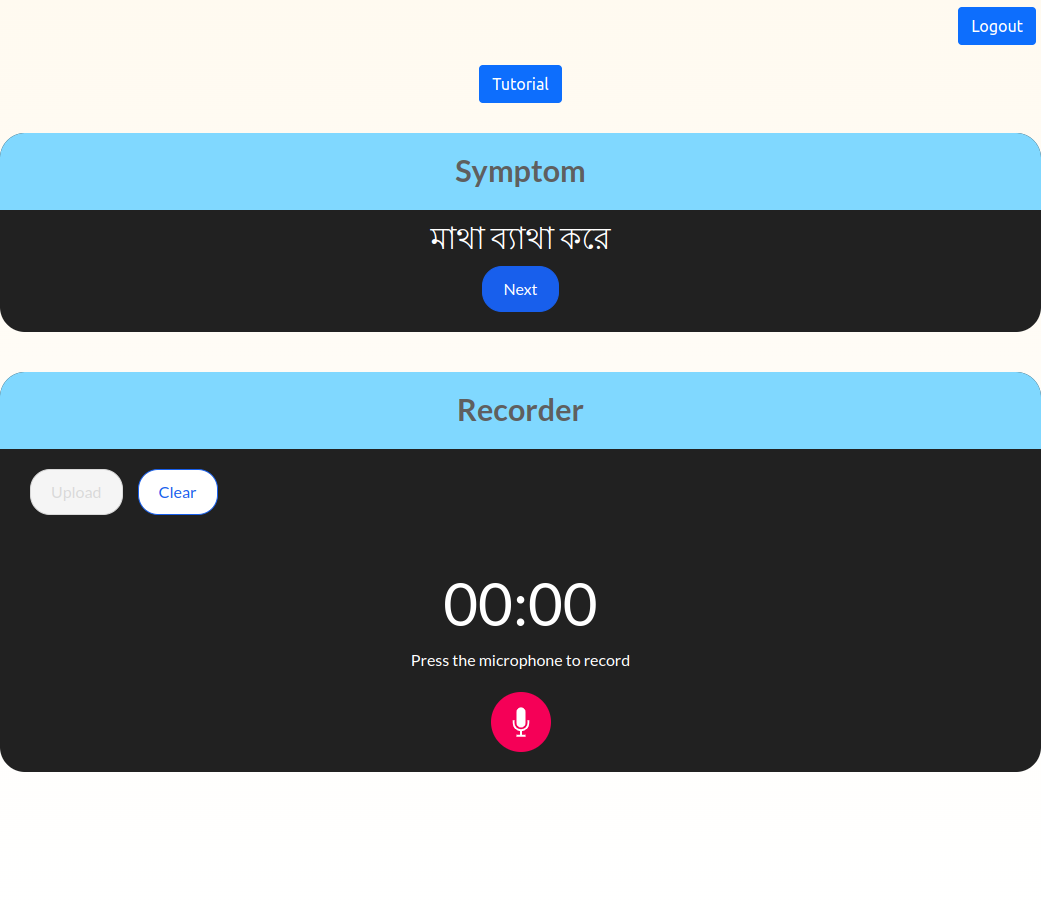
- [6/16/2024] The preprint of our work on Automatic Speech Recognition for Biomedical Data in Bengali Language is available on arXiv.
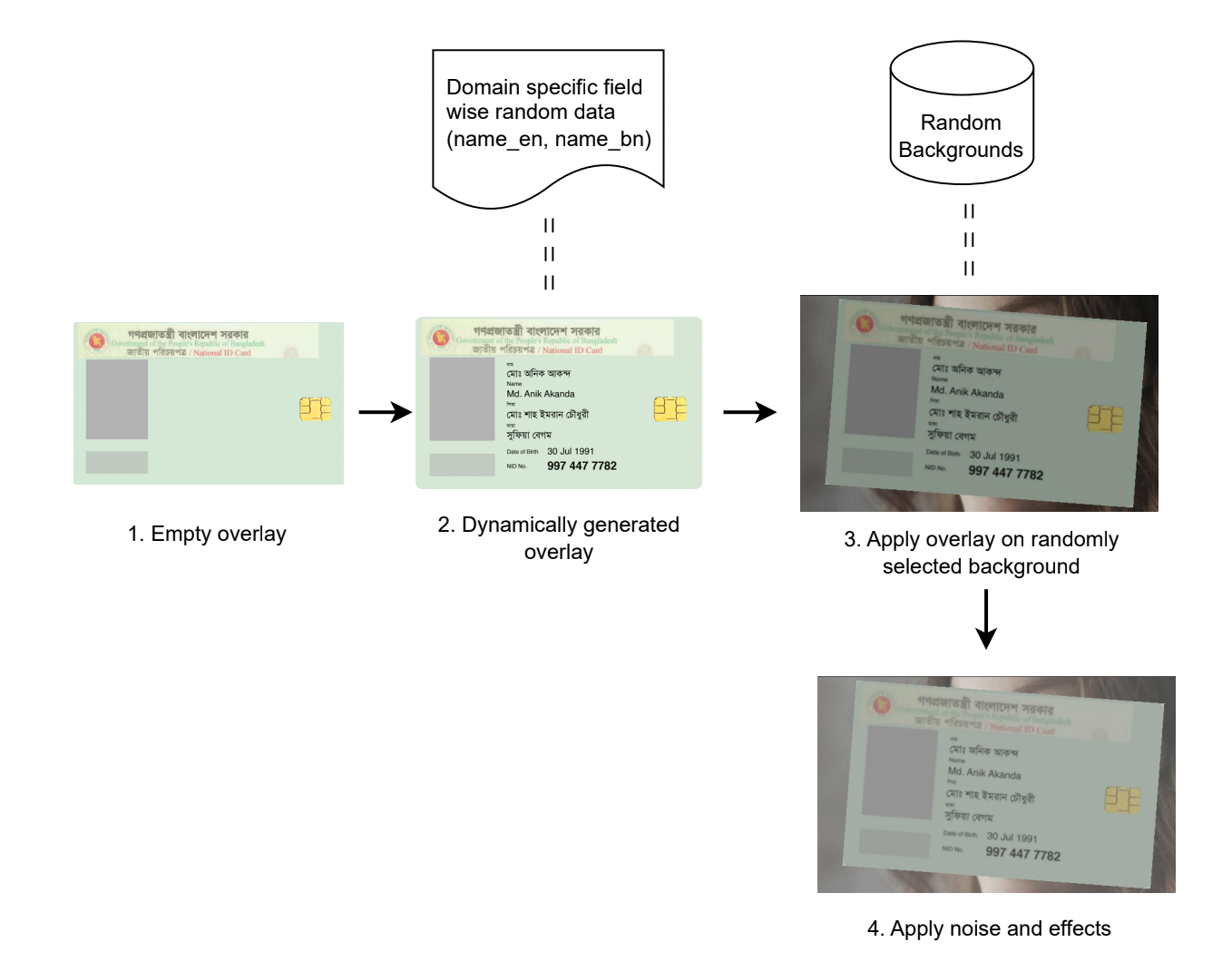
- [10/11/2023] Our paper SynthNID: Synthetic Data to Improve End-to-end Bangla Document Key Information Extraction has been accepeted at BLP workshop at EMNLP 2023.